
Enabling Stable Long Human Animation with Any Video DiTs
Recent DiT-based human animation models deliver impressive results—but only for a few seconds.
Our Lookahead Anchoring is a simple-yet-effective method designed to stay stable against error accumulation and identity drift, even within straightforward temporal autoregressive approaches.
HunyuanAvatar* / HunyuanAvatar* + Ours
(* HunyuanAvatar is modified to take 5 starting frames for autoregressive generation scheme.)
OmniAvatar / OmniAvatar + Ours
Keyframe ahead of Generation Window
Traditional keyframe-based approaches follow a two-step pipeline: keyframe generation → video interpolation, where keyframes typically mark the start and end of each segment.
When audio drives the generation, keyframes must be audio-synced. This rigid constraint forces the video to hit exact facial poses at fixed timestamps, limiting motion expressiveness and dynamics.
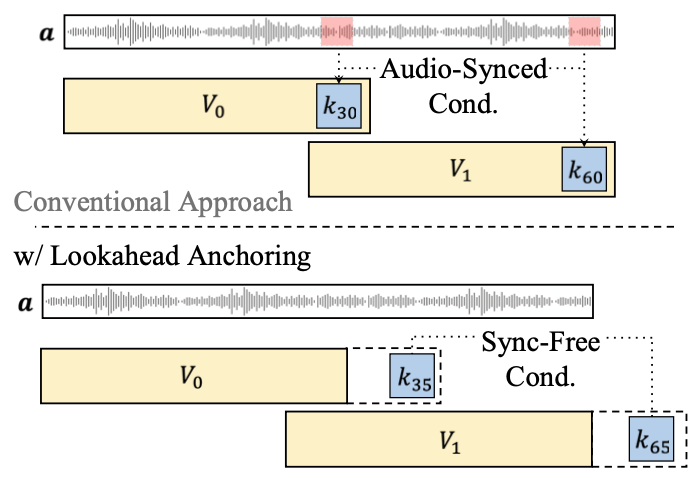
Distant keyframes eliminate audio-sync stage.
But what if keyframes don't have to be in the generated video? What if we place them beyond the segment endpoints—further ahead in time?
We explore this idea. By positioning keyframes ahead of the generation window, they transform from rigid constraints into soft directional guidance. This dramatically simplifies the framework while delivering superior performance.
KeyFace (keyframe-based approach) / Ours
Temporal Distance as a Conditioning Strength
Models naturally learn that longer temporal distances allow for greater scene variation. We exploit this prior strategically: distant keyframes provide high-level guidance without imposing strict physical constraints, enabling diverse yet coherent generation.

Temporal distance 𝐷 reflects inter-frame relevance.
Abstract
Citation
Related Work
- • KeyFace: Expressive Audio-Driven Facial Animation for Long Sequences
- • Sonic: Shifting Focus to Global Audio Perception in Portrait Animation
- • Packing Input Frame Context in Next Frame Prediction Models
- • HunyuanVideo-Avatar: High-Fidelity Audio-Driven Human Animation
- • OmniAvatar: Efficient Audio-Driven Avatar Video Generation
- • Hallo3: Highly Dynamic and Realistic Portrait Image Animation
Acknowledgements
TBD. The website template was borrowed from Michaël Gharbi.